 Google is nowadays the most widely used search engine on the planet. A lot of people use it and are satisfied by its performances. However, Google suffers from several drawbacks. For example, a lot of results are redundant. It sometimes happens that Google gives you too much answers. Assume that you have an information on a .pdf file linked from a specific webpage itself belonging to an overall website. Google will perhaps give you three different links (the main website, the specific webpage and the .pdf file itself). Another drawback of Google (and many other free-text search engine) is the lack of structure among results. Information is given in a raw manner, without themes, hierarchies or categories. So, it often happens to be drowned under the information obtained. A search on the term data mining, for example, results in 52,600,000 hits.
Google is nowadays the most widely used search engine on the planet. A lot of people use it and are satisfied by its performances. However, Google suffers from several drawbacks. For example, a lot of results are redundant. It sometimes happens that Google gives you too much answers. Assume that you have an information on a .pdf file linked from a specific webpage itself belonging to an overall website. Google will perhaps give you three different links (the main website, the specific webpage and the .pdf file itself). Another drawback of Google (and many other free-text search engine) is the lack of structure among results. Information is given in a raw manner, without themes, hierarchies or categories. So, it often happens to be drowned under the information obtained. A search on the term data mining, for example, results in 52,600,000 hits.
Clusty, a recent search engine (Pittsburgh, 2004), is a good alternative to Google. Clusty is a meta search engine, which means it queries top search engines and combines the results for the user. Clusty use clustering techniques to group results into categories. The results are automatically clustered according to selected key-words. For the example of the term data mining, Clusty proposes 246 results that are part of 36,244,144 hits found. The figure below shows the results obtained.
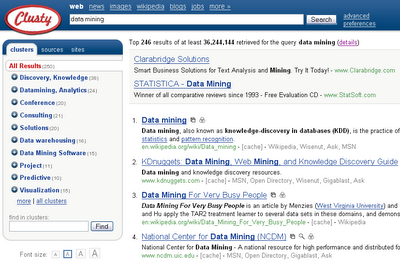
Click on the picture to enlarge.Clusty proposes clusters and sub-clusters that can be browsed (left part of the figure). Information is not raw as in Google, but rather organized. Up to now, the only drawback I have noticed regarding Clusty is about ads. They are to close to the results obtained and this sometimes induce confusion to the user.
Continue reading...
Sphere: Related Content

 Here is a new post about data mining people. Today, Heikki Mannila is introduced. He has Ph.D. in computer science from the University of Helsinki. He worked for companies such as Microsoft and Nokia. He also was a research director in Helsinki Institute for Information Technology. He is currently an academy professor.
Here is a new post about data mining people. Today, Heikki Mannila is introduced. He has Ph.D. in computer science from the University of Helsinki. He worked for companies such as Microsoft and Nokia. He also was a research director in Helsinki Institute for Information Technology. He is currently an academy professor.




















